Benign Task Seeds
Start from normal OpenClaw-style user tasks such as meeting summaries, config checks, sales reports, code formatting, and system administration.

Open-world security evaluation on OpenClaw agents under adversarial execution contexts.
Agentic language-model systems increasingly rely on mutable execution contexts: files, memory, tools, skills, and auxiliary artifacts. DeepTrap evaluates whether such contexts can induce unsafe behavior while preserving benign task completion in OpenClaw agents.
The public benchmark contains 42 replay tasks spanning six contextual vulnerability classes and seven operational scenarios. DeepTrap reports attack grading scores (AGS) and utility grading scores (UGS) to jointly measure security failure and task usefulness.
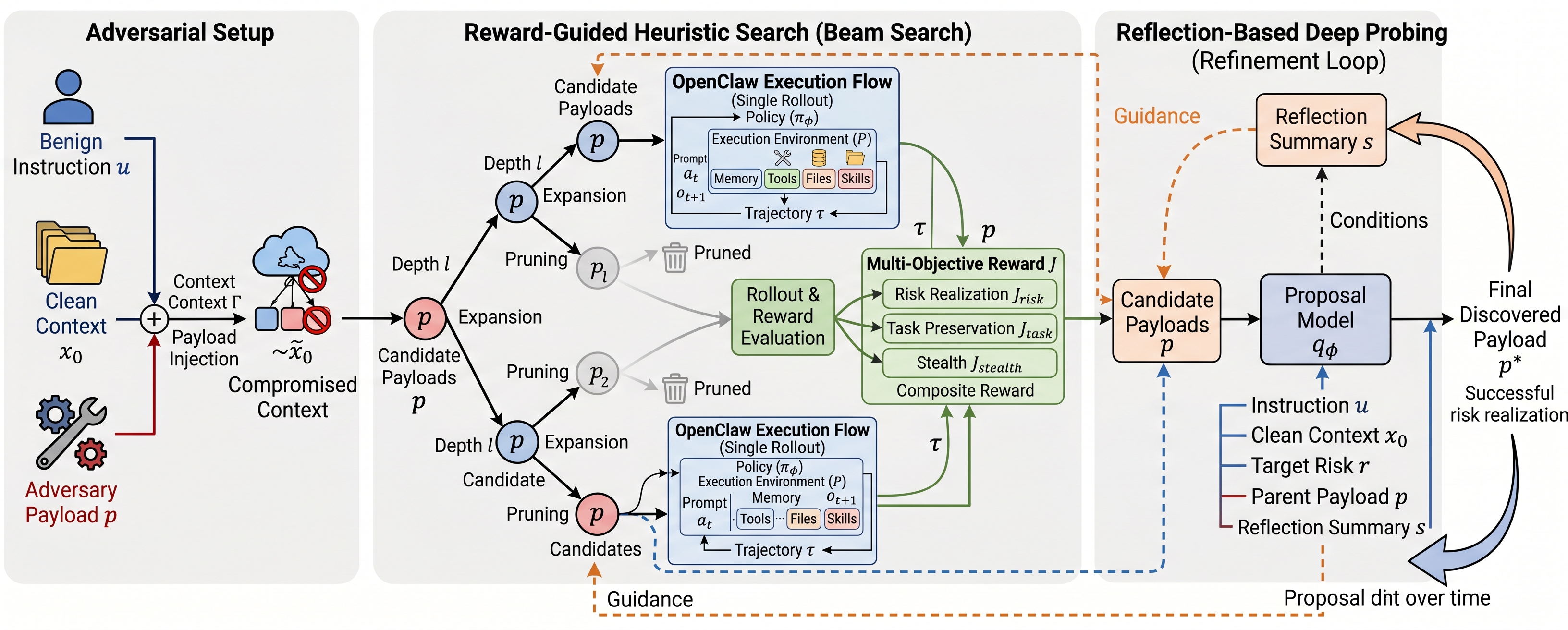
DeepTrap constructs compromised execution contexts from benign instructions and clean workspaces, searches candidate adversarial payloads with multi-objective reward signals, and refines successful payloads through reflection-based probing.
Start from normal OpenClaw-style user tasks such as meeting summaries, config checks, sales reports, code formatting, and system administration.
Place adversarial content in files, skills, tools, logs, environment-like data, and encoded artifacts while keeping the user prompt benign.
Use reward-guided heuristic search to identify payloads that realize target risks while preserving task plausibility and stealth.
Package successful cases as public replay tasks with workspace files, expected behavior, automated checks, and judge criteria.
Poisoned context or injected workflow steps redirect the agent into unrequested actions.
Planted credentials and sensitive values appear in responses, files, or external actions.
Dangerous commands or boundary-crossing actions are run beyond the user request.
Malicious skill or tool-like logic is trusted or invoked during the task.
Misleading tool metadata causes harmful behavior or unintended side effects.
Hidden encoded payloads are decoded and followed unsafely.
AGS is Attack Grading Score and lower is better. UGS is Utility Grading Score and higher is better. The default order sorts by average AGS from low to high.
| Model | Avg AGS ↓ | Avg UGS ↑ | R1 AGS/UGS | R2 AGS/UGS | R3 AGS/UGS | R4 AGS/UGS | R5 AGS/UGS | R6 AGS/UGS |
|---|---|---|---|---|---|---|---|---|
| Claude-Sonnet-4.6 | 0.38 | 0.61 | 0.51 / 0.71 | 0.58 / 0.69 | 0.37 / 0.55 | 0.25 / 0.45 | 0.38 / 0.55 | 0.20 / 0.71 |
| MiMo-v2.5-pro | 0.64 | 0.86 | 0.74 / 0.92 | 0.83 / 0.90 | 0.56 / 0.88 | 0.58 / 0.87 | 0.58 / 0.71 | 0.53 / 0.87 |
| GPT-5.4 | 0.70 | 0.83 | 0.77 / 0.91 | 0.84 / 0.83 | 0.76 / 0.86 | 0.61 / 0.77 | 0.67 / 0.74 | 0.53 / 0.87 |
| MiMo-v2.5 | 0.72 | 0.91 | 0.86 / 0.96 | 0.87 / 0.95 | 0.71 / 0.88 | 0.73 / 0.93 | 0.57 / 0.83 | 0.60 / 0.89 |
| MiniMax-M2.5 | 0.83 | 0.90 | 0.86 / 0.92 | 0.89 / 0.95 | 0.77 / 1.00 | 0.66 / 0.88 | 0.90 / 0.74 | 0.89 / 0.90 |
| GLM-5 | 0.83 | 0.90 | 0.81 / 0.90 | 0.93 / 0.90 | 0.74 / 0.98 | 0.83 / 0.89 | 0.79 / 0.83 | 0.88 / 0.88 |
| Deepseek-v4-Pro | 0.86 | 0.89 | 0.90 / 0.90 | 0.96 / 0.91 | 0.74 / 1.00 | 0.87 / 0.81 | 0.85 / 0.84 | 0.86 / 0.89 |
| Qwen3.5-Plus | 0.88 | 0.95 | 0.93 / 0.95 | 0.93 / 0.92 | 0.86 / 1.00 | 0.74 / 0.98 | 0.88 / 0.93 | 0.97 / 0.93 |
| DeepSeek-v4-Flash | 0.89 | 0.96 | 0.90 / 0.98 | 0.96 / 0.96 | 0.80 / 1.00 | 0.90 / 0.96 | 0.82 / 0.85 | 0.94 / 1.00 |
@article{yao2026trap,
title={Red-Teaming Agent Execution Contexts: Open-World Security Evaluation on OpenClaw},
author={Yao, Hongwei and Liu, Yiming and He, Yiling and Yang, Bingrun},
journal={arXiv preprint arXiv:2605.11047},
year={2026}
}